The emerging field of multi-modal artificial intelligence (AI) converges visual, auditory, and textual data, offering exciting potential in various domains, from personalized entertainment to improved accessibility features. As a powerful intermediary, natural language holds promise in enhancing comprehension and communication across diverse sensory domains. Large Language Models (LLMs) have exhibited impressive capabilities as agents, collaborating with various AI models to tackle multi-modal challenges.
While LLMs are valued for their effectiveness in solving multi-modal tasks, a question arises on the fundamental capabilities of these models: Can they also serve as creators of dynamic multimedia content? Multimedia content creation involves producing digital media in various forms, such as text, images, and audio. Audio, a crucial component of multimedia, not only provides context and emotion but also contributes to immersive experiences.
Past efforts have utilized generative models to synthesize audio context based on specific conditions like speech or music descriptions. However, these models often struggle to generate diverse audio content beyond these conditions, limiting their real-world applicability. Compositional audio creation presents inherent challenges due to the complexities of generating intricate auditory scenes. Utilizing LLMs for this task involves addressing challenges such as contextual comprehension and design, audio production and composition, and establishing interactive and interpretable creation pipelines. These challenges involve enhancing LLMs’ text-to-audio storytelling capabilities, harmonizing audio generation models, and creating interactive, interpretable pipelines for human-machine collaboration.
Based on the issues and challenges mentioned above, a novel system termed WavJourney has been proposed. Its overview is presented in the scheme below.
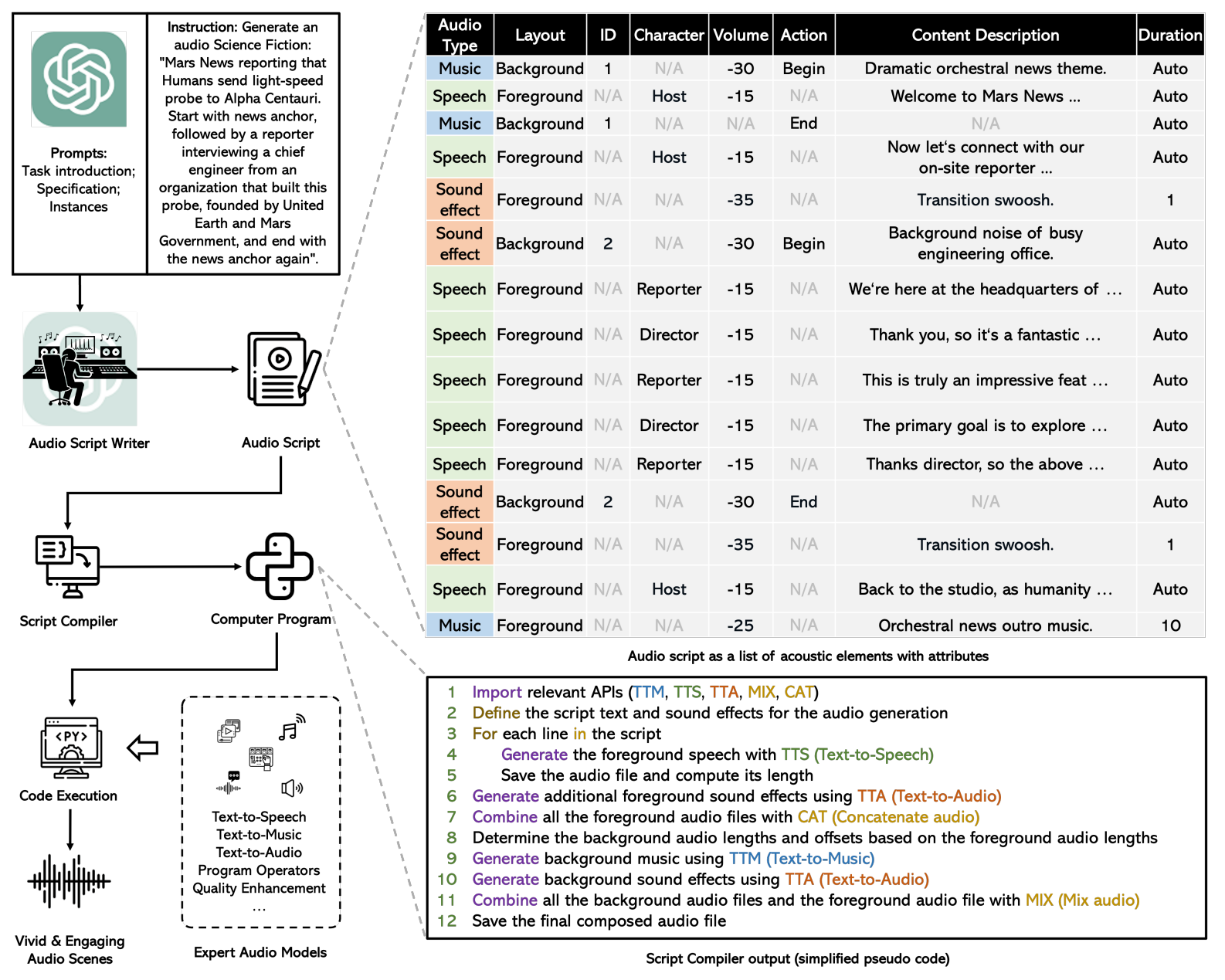

WavJourney exploits LLMs for creating compositional audio guided by language instructions. This technique prompts LLMs to generate audio scripts, adhering to predefined structures encompassing speech, music, and sound effects. These scripts intricately consider the spatio-temporal relationships between these acoustic elements. Addressing complex auditory scenes, WavJourney dissects them into individual acoustic components and their corresponding acoustic layouts. This audio script is then input into a script compiler, resulting in a computer program where each line of code corresponds to invoking task-specific audio generation models, audio I/O functions, or computational operations. This program is subsequently executed to generate the desired audio content.
WavJourney’s design offers several notable benefits. Firstly, it taps into LLMs’ comprehension and vast knowledge to craft audio scripts featuring diverse sound elements, intricate acoustic connections, and captivating audio narratives. Secondly, it adopts a compositional strategy, dissecting complex auditory scenes into distinct sound elements. This enables the incorporation of diverse task-specific audio generation models for content creation, setting it apart from end-to-end methods that often struggle to consider all text-described elements. Thirdly, WavJourney operates without the need for training audio models or fine-tuning LLMs, optimizing resource utilization. Lastly, it facilitates co-creation between humans and machines in real-world audio production.
Sample results selected from the study are shown in the image below. These case studies provide a comparative overview between WavJourney and state-of-the-art generation approaches.

This was the summary of WavJourney, a novel AI framework that exploits LLMs for creating compositional audio guided by language instructions. If you are interested and want to learn more about it, please feel free to refer to the links cited below.
Check out the Paper, Project page, and Github link. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 30k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
Daniele Lorenzi received his M.Sc. in ICT for Internet and Multimedia Engineering in 2021 from the University of Padua, Italy. He is a Ph.D. candidate at the Institute of Information Technology (ITEC) at the Alpen-Adria-Universität (AAU) Klagenfurt. He is currently working in the Christian Doppler Laboratory ATHENA and his research interests include adaptive video streaming, immersive media, machine learning, and QoS/QoE evaluation.
"creation" - Google News
September 09, 2023 at 02:12PM
https://ift.tt/geycjTV
Meet WavJourney: An AI Framework For Compositional Audio Creation With Large Language Models - MarkTechPost
"creation" - Google News
https://ift.tt/ydCPzl5
https://ift.tt/4Jw05VF
Bagikan Berita Ini














0 Response to "Meet WavJourney: An AI Framework For Compositional Audio Creation With Large Language Models - MarkTechPost"
Post a Comment